
加上两个反斜杠代表一个反斜杠 或者在前面加一个r
两个字符串合并 加号
ord 将字符转成数字
chr 将数字装换成为字母

加上两个反斜杠代表一个反斜杠 或者在前面加一个r
两个字符串合并 加号
ord 将字符转成数字
chr 将数字装换成为字母
\——转义符
\uffff unicode16位的16进制值
\xff 16进制值
\off 8进制值
\r 返回
\n 换行
\b 倒退
raw 不转译
len() 算长度
+合并
*重复
ord 转数字
chr 转字符
unichr 转Unicode
任务5、字符串
一 Python中的字符串
1、介绍
字符串可以包含数字、字母、中文字符、特殊符号,以及一些不可见的控制字符,如换行符和制表符。
2、举例
>>> str1 ='abcd'>>> str2 ='python'>>> str3 ='123'>>> str4 ='a = 1*7 + 8'>>> str5 ='can\'t'>>> str5"can't">>> str6 ="can't">>> str6"can't3.转义

在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:
原始字符串
有时我们并不想让转义字符生效,我们只想显示字符串原来的意思,这就要用r和R来定义原始字符串。如:
print r'\t\r'
实际输出为“\t\r”。
基本操作:
1、去空格及特殊符号
s.strip().lstrip().rstrip(',')
2、复制字符串
#strcpy(sStr1,sStr2)
sStr1 = 'strcpy'
sStr2 = sStr1
sStr1 = 'strcpy2'
print sStr2
3、连接字符串
#strcat(sStr1,sStr2)
sStr1 = 'strcat'
sStr2 = 'append'
sStr1 += sStr2
print sStr1
4、查找字符
#strchr(sStr1,sStr2)
# < 0 为未找到
sStr1 = 'strchr'
sStr2 = 's'
nPos = sStr1.index(sStr2)
print nPos
5、比较字符串
#strcmp(sStr1,sStr2)
sStr1 = 'strchr'
sStr2 = 'strch'
print cmp(sStr1,sStr2)
6、扫描字符串是否包含指定的字符
#strspn(sStr1,sStr2)
sStr1 = '12345678'
sStr2 = '456'
#sStr1 and chars both in sStr1 and sStr2
print len(sStr1 and sStr2)
7、字符串长度
#strlen(sStr1)
sStr1 = 'strlen'
print len(sStr1)
8、将字符串中的大小写转换
S.lower() #小写
S.upper() #大写
S.swapcase() #大小写互换
S.capitalize() #首字母大写
String.capwords(S) #这是模块中的方法。它把S用split()函数分开,然后用capitalize()把首字母变成大写,最后用join()合并到一起
#实例:
#strlwr(sStr1)
sStr1 = 'JCstrlwr'
sStr1 = sStr1.upper()
#sStr1 = sStr1.lower()
print sStr1
9、追加指定长度的字符串
#strncat(sStr1,sStr2,n)
sStr1 = '12345'
sStr2 = 'abcdef'
n = 3
sStr1 += sStr2[0:n]
print sStr1
10、字符串指定长度比较
#strncmp(sStr1,sStr2,n)
sStr1 = '12345'
sStr2 = '123bc'
n = 3
print cmp(sStr1[0:n],sStr2[0:n])
11、复制指定长度的字符
#strncpy(sStr1,sStr2,n)
sStr1 = ''
sStr2 = '12345'
n = 3
sStr1 = sStr2[0:n]
print sStr1
12、将字符串前n个字符替换为指定的字符
#strnset(sStr1,ch,n)
sStr1 = '12345'
ch = 'r'
n = 3
sStr1 = n * ch + sStr1[3:]
print sStr1
13、扫描字符串
#strpbrk(sStr1,sStr2)
sStr1 = 'cekjgdklab'
sStr2 = 'gka'
nPos = -1
for c in sStr1:
if c in sStr2:
nPos = sStr1.index(c)
break
print nPos
14、翻转字符串
#strrev(sStr1)
sStr1 = 'abcdefg'
sStr1 = sStr1[::-1]
print sStr1
15、查找字符串
#strstr(sStr1,sStr2)
sStr1 = 'abcdefg'
sStr2 = 'cde'
print sStr1.find(sStr2)
16、分割字符串
#strtok(sStr1,sStr2)
sStr1 = 'ab,cde,fgh,ijk'
sStr2 = ','
sStr1 = sStr1[sStr1.find(sStr2) + 1:]
print sStr1
#或者
s = 'ab,cde,fgh,ijk'
print(s.split(','))
17、连接字符串
delimiter = ','
mylist = ['Brazil', 'Russia', 'India', 'China']
print delimiter.join(mylist)
18、PHP 中 addslashes 的实现
def addslashes(s):
d = {'"':'\\"', "'":"\\'", "\0":"\\\0", "\\":"\\\\"}
return ''.join(d.get(c, c) for c in s)
s = "John 'Johny' Doe (a.k.a. \"Super Joe\")\\\0"
print s
print addslashes(s)
19、只显示字母与数字
def OnlyCharNum(s,oth=''):
s2 = s.lower();
fomart = 'abcdefghijklmnopqrstuvwxyz0123456789'
for c in s2:
if not c in fomart:
s = s.replace(c,'');
return s;
print(OnlyStr("a000 aa-b"))
20、截取字符串
str = '0123456789′
print str[0:3] #截取第一位到第三位的字符
print str[:] #截取字符串的全部字符
print str[6:] #截取第七个字符到结尾
print str[:-3] #截取从头开始到倒数第三个字符之前
print str[2] #截取第三个字符
print str[-1] #截取倒数第一个字符
print str[::-1] #创造一个与原字符串顺序相反的字符串
print str[-3:-1] #截取倒数第三位与倒数第一位之前的字符
print str[-3:] #截取倒数第三位到结尾
print str[:-5:-3] #逆序截取,具体啥意思没搞明白?
21、字符串在输出时的对齐
S.ljust(width,[fillchar])
#输出width个字符,S左对齐,不足部分用fillchar填充,默认的为空格。
S.rjust(width,[fillchar]) #右对齐
S.center(width, [fillchar]) #中间对齐
S.zfill(width) #把S变成width长,并在右对齐,不足部分用0补足
22、字符串中的搜索和替换
S.find(substr, [start, [end]])
#返回S中出现substr的第一个字母的标号,如果S中没有substr则返回-1。start和end作用就相当于在S[start:end]中搜索
S.index(substr, [start, [end]])
#与find()相同,只是在S中没有substr时,会返回一个运行时错误
S.rfind(substr, [start, [end]])
#返回S中最后出现的substr的第一个字母的标号,如果S中没有substr则返回-1,也就是说从右边算起的第一次出现的substr的首字母标号
S.rindex(substr, [start, [end]])
S.count(substr, [start, [end]]) #计算substr在S中出现的次数
S.replace(oldstr, newstr, [count])
#把S中的oldstar替换为newstr,count为替换次数。这是替换的通用形式,还有一些函数进行特殊字符的替换
S.strip([chars])
#把S中前后chars中有的字符全部去掉,可以理解为把S前后chars替换为None
S.lstrip([chars])
S.rstrip([chars])
S.expandtabs([tabsize])
#把S中的tab字符替换没空格,每个tab替换为tabsize个空格,默认是8个
23、字符串的分割和组合
S.split([sep, [maxsplit]])
#以sep为分隔符,把S分成一个list。maxsplit表示分割的次数。默认的分割符为空白字符
S.rsplit([sep, [maxsplit]])
S.splitlines([keepends])
#把S按照行分割符分为一个list,keepends是一个bool值,如果为真每行后而会保留行分割符。
S.join(seq) #把seq代表的序列──字符串序列,用S连接起来
24、字符串的mapping,这一功能包含两个函数
String.maketrans(from, to)
#返回一个256个字符组成的翻译表,其中from中的字符被一一对应地转换成to,所以from和to必须是等长的。
S.translate(table[,deletechars])
# 使用上面的函数产后的翻译表,把S进行翻译,并把deletechars中有的字符删掉。需要注意的是,如果S为unicode字符串,那么就不支持 deletechars参数,可以使用把某个字符翻译为None的方式实现相同的功能。此外还可以使用codecs模块的功能来创建更加功能强大的翻译表。
25、字符串还有一对编码和解码的函数
S.encode([encoding,[errors]])
# 其中encoding可以有多种值,比如gb2312 gbk gb18030 bz2 zlib big5 bzse64等都支持。errors默认值为"strict",意思是UnicodeError。可能的值还有'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 和所有的通过codecs.register_error注册的值。这一部分内容涉及codecs模块,不是特明白
S.decode([encoding,[errors]])
26、字符串的测试、判断函数,这一类函数在string模块中没有,这些函数返回的都是bool值
S.startswith(prefix[,start[,end]])
#是否以prefix开头
S.endswith(suffix[,start[,end]])
#以suffix结尾
S.isalnum()
#是否全是字母和数字,并至少有一个字符
S.isalpha() #是否全是字母,并至少有一个字符
S.isdigit() #是否全是数字,并至少有一个字符
S.isspace() #是否全是空白字符,并至少有一个字符
S.islower() #S中的字母是否全是小写
S.isupper() #S中的字母是否便是大写
S.istitle() #S是否是首字母大写的
27、字符串类型转换函数,这几个函数只在string模块中有
string.atoi(s[,base])
#base默认为10,如果为0,那么s就可以是012或0x23这种形式的字符串,如果是16那么s就只能是0x23或0X12这种形式的字符串
string.atol(s[,base]) #转成long
string.atof(s[,base]) #转成float
Python的类型与运算-字符串(一)
内容:
• 字符串简介
• 字符串常量
• 字符串操作
• 字符串方法(函数)
• 字符串格式化表达式
在Python里字符串是一个有序的字符的集合,用来存储和表现基于文本的信息。字符串可以用来表示能够像文本那样编辑的任何信息:符号和词语、在入道内存中的文本的内容、Internet网址和Python程序等。
在Python里字符串被划分为不可变序列这一类别,这意味着这些字符串所包含的字符存在从左至右的位置顺序,并且他们不可以在原处修改。
在Python里有很多种方法来表示字符串:
• 单引号:'Text"1"'
字符串代码转换: 当我们需要对字符串大小写等操作的时候,需要对字符串转换成相应的代码。这个时候我们就需要两个函数:ord和chr。
ord是把一个字符转换成数字,chr是把数字转换成单个字符。
• 双引号:"Text'1'"
• 三引号:'''...Lines...''',"""...Lines...""".
• 转义字符:"Line1\taddedtab\nLine2"
• Raw字符串:r"C:\My\new\Directory\file.exe"
防止的是转义字符。
• Python 3.x中的Byte字符串:b'Te\x01xt'
• Python 2.x中的Unicode字符串:u'my\u0020text'
在Python 3.x里默认是使用Unicode方式存储字符串。
在Python 2.x里默认是使用Latin-1方式存储字符串,因此不能直接识别中文。
# -*- encoding=utf8 -*-
在Python2.x脚本文件加上上面一句话就能正常使用中文。
Python转义字符:\(反斜杠)
len()是看字符串长度的。这个在使用中文的时候,会有点不同。
ord函数:把字符转化为数字
chr函数:把数字转化为单个字符
判断某个字符是否在一个字符串:可以用in或者not in来判断
ord(x):把一个字符转换成数字
chr(x):把数字转换成单个字
字符串 不可变序列,但是 是不可修改的对象
#-*-encoding=utf8-*- 正常使用中文
text.replace('char','char')
转义字符 \
\newLine
\\反斜杠
\"双引号
负数坐标表示倒过来
ord()把字符转换成数字
chr()把数字转换成字符
Python 2 直接使用中文会出错
字符串可以直接比较大小
字符串合并 用+即可
字符串的重复输出 可以使用*
使用in 或者not in来判断是否属于同一个字符串
分片操作每隔n个字符显示
例:text="ThisIsTestText"
text[::2]的结果是:'TiITsTx'
字符串代码转换:当我们需要对字符串大小写等操作的时候,需要对字符串转换成相应的代码。这个时候我们就需要两个函数:ord和chr。ord是把一个字符串转换成数字,chr是把数字转换成单个字符
unichr可以转换回去(转换为汉字)
replace 替换字符串 返回的是一个字符串
如果想要改变原来的字符串的话,需要对原来的字符串重新赋值
不可变序列
#-*-encoding=utf8-*-这样python脚本就能用中文了
'a"b\'c'为a"b'c
"a\"b'c"为a"b'c
a='hello\这里加个空格不行
askdj'连在一起
\b光标往回
\f换页一列,但是在linux下用和\v效果一样,在windows下却奇奇怪怪
\v换行同一列
\r光标移到第一个位
\uhhhh,用16位16进制表示比如\u0041表示'A'
\u0000 0041也表示'A'不过是32位的
\xhh也一样16进制
\ooo八进制
len(a)可以看长度
\0表示空字符,不显示的
在py2中
len('中文')3个字符
len(u'中文')2个
'hi'*5
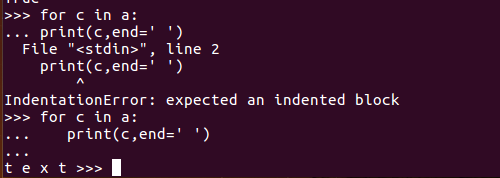
for c in a:print(c,end=' ')这样就不会换行了2.7要用这个功能要引入from __future__ import print_function
a[0:5]0到5或a[:5]开始不用写
a[-4:]结束不用写后面4个倒数最后一个a[-1]
a[::2]每两个显示一个a[1::2]1是开始的位置
a[::-1]从后面倒过来
a[::]和输出a一样间隔默认为1和a[::1]一样
a[-3:3:-1]表示逆向从-3到3
ord('a')换成数字py2.7不能用中文,加u就可以了
chr(89)数字转换成字母
unichr(2003)是中
2.7: unichr(u'啊')
a='dahl' 不能用a[1]这样来索引
text.replace('','')创建一个新值可用
text=text.replace来修改
在Python里字符串属于一个不可变序列类型的对象类别,意味着这些字符串所包含的字符存在从左至右的位置顺序,而且他们不可以在原处修改。
Raw字符串在不想要转义字符串的前面加r r"C:\My\new\Directory\file.exe"
三引号 可来写两行以上的字符串
Python3.x 有Byte字符串:b'Te\x01xt' 默认是使用Unicode的方式储存字符串 python2.x 有Unicode字符串 u'my\u0020text' 默认是使用Latin-1的方式储存字符串,因此不能识别中文。 加上这句话 #-*-encoding=utf8-*- 才能正常使用中文。
\f是换页 \v是同一列换行
len()函数与c中不同,是所有的字符(包括\0)
'Hi!'*3 'Hi!Hi!Hi!'
a='0123456789' print(a[2:3])==>2 print(a[2:])==>23456789 print(a[:-1])==>012345678
ord函数查看ASCII python2.x中查看中文时,前面要加u 即ord(u'中')
a.replace('123','-') ==> 0---456789 a的值不会改变。
a=a.replace('123','-') a的值才会改变
未来之巳
2018.5.21
====字符串
python中 内存分配取决于底层的编译器
查看内存占用字节数
len(变量)
组成新字符串
a='lao'
b='wang'
c=a+b #>>>c 'laowang'
d=100
e=200
f=d+e #>>>f 300
g='==='+a+b+'===' #>>>g '===laowang==='
h='===%s==='%(a+b) #>>>h '===laowang===' python3中字符串拼接可以使用引用的方式
==字符串下标
name = 'abcdef'
>>>name[2]
c
#字符串下标从0开始
IndexError:out of range下标越界
==取最后一个字母
name[len(name)-1]
name[-1]
==字符串切片
>>>name[2:5] #从2到5
'cde'
>>>name[2:-1] #从2到最后的前一位
'cde'
>>>name[2:] #从2到最后
'cdef'
==间隔一位,切片
>>>name[2:-1:2] #从2到最后的前一位,并且隔一位一取
'ce'
#name[起始位置:终止位置:步长]
默认步长为1
==逆序
>>>name[-1:0:-1]
fedcb
>>>name[-1::-1]
fedcba
>>>name[::-1]
fedcba
#起始点与截止点根据步长有关
==常见函数
myStr = "hello world itcast and itcastxxxcpp"
myStr.这时候按TAB会显示字符串的常见操作
>>>myStr.find('world')
6 #返回开头字母的下标
>>>myStr.find('dog')
-1 #找不到为-1
从左边开始找
>>>myStr.rfind('itcast')
23
==替换
>>>myStr.replace('world','WORLD')
hello WORLD itcast and itcastxxxcpp
>>>myStr
hello world itcast and itcastxxxcpp #字符串为不可变类型,仅返回新字符串,旧值不变
replace('','',num) #替换几个
==切割
>>>myStr.split()
myStr.split()#默认可以将空格与转义字符删掉并切割字符串,返回list
再使用.join拼接回字符串
==开头大写小写
myStr.capitalize() #小写
myStr.title() #大写
==判断以什么开头,以什么结尾
file_name = 'xxx.txt'
file_name.endswith('.txt')
file_name.startswith('wang')
#返回值为布尔型
==大小写转换(所有)
.lower
.upper
>>>
字符串合并:'xxxxx'+'xxxxx'
字符串重复:'xx' * n(n为需要重复的次数)
python2为了正常使用中文,可以在脚本的开头加上语句:#-*-encoding=utf8-*-来所有的字符串方式都转换为utf8的方式.
len():用来看字符串的长度。
在用for语句时,要记得缩进,不然会报错(前面加上先执行语句:from __future__ import print_function)。
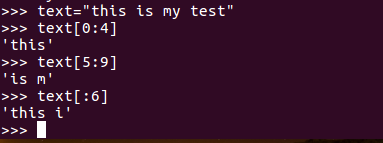
string[a:b:c]表示提取从a开始到b的字符串。(最后一个参数可有可无,表示每c个字符显示一个)。
ord():把一个字符串转换位数字。
chr():把单个数字转换为字符。
python3.x :默认是 unicode 存储、输出字符串
python 3.x :
print (a,end = ‘\n ’)以什么结尾
ord(‘a’):字符转数字(ASCII)
chr(97):数字(ASCII)转字符
大写字母比小写字母小 32 (ASCII)
string.replace(“aaa”,‘ss’):
用 “ss”替换string 中的 “aaa”